Brain Tumor Detection and Classification Using Convolutional Neural Networks
Undergraduate Thesis — Software Engineering, Sichuan University · Fall 2021
TL;DR
- Lightweight CNN trained from scratch for brain tumor MRI detection & classification (four classes: glioma, meningioma, pituitary, no tumor), targeting small, imbalanced data and limited compute.
- 98% validation accuracy; matched or outperformed VGG-16, Xception, ResNet-50, and Inception-V3.
Research problem & motivation
Accurate brain tumor detection & classification from MRI is a clinically critical task, yet many deep learning approaches depend on large pre-trained networks that require substantial computational resources and extensive labeled data. In practice, medical imaging datasets are often small, imbalanced, and heterogeneous, making such models prone to overfitting and limiting their applicability in real clinical environments.
This research is motivated by the need for computationally efficient and data-efficient diagnostic models. The central problem addressed is whether a carefully designed CNN trained from scratch can achieve competitive multi-class brain tumor classification performance without relying on transfer learning. By prioritizing architectural simplicity, appropriate preprocessing, and data augmentation, this work aims to balance diagnostic accuracy with practical deployability, particularly in resource-constrained clinical settings.
Dataset & preprocessing
Dataset context
The study uses the Brain Tumor MRI Dataset on Kaggle, comprising 7,023 T1-weighted contrast-enhanced MRI scans in four classes: glioma, meningioma, pituitary tumor, and no tumor. The dataset is relatively small and class-imbalanced, motivating careful preprocessing and augmentation. Images were partitioned into training and testing subsets, with each tumor category represented in both splits. Image sizes vary across the dataset; resizing and normalization were applied during preprocessing (see below).
Dataset composition
| Class | Training | Testing | Total |
|---|---|---|---|
| Glioma | 1,321 | 300 | 1,621 |
| Meningioma | 1,339 | 306 | 1,645 |
| Pituitary tumor | 1,457 | 300 | 1,757 |
| No tumor | 1,595 | 405 | 2,000 |
| Total | 5,712 | 1,311 | 7,023 |
Table 1. Distribution of MRI images across training and testing sets.
Image preprocessing
Raw MRI scans contain substantial non-informative background regions, which can negatively affect feature learning. To address this, each image was preprocessed using a cropping-based region-of-interest (ROI) extraction procedure (Figure 1). This step focuses the model’s attention on the brain area, reduces background noise, and improves learning efficiency.
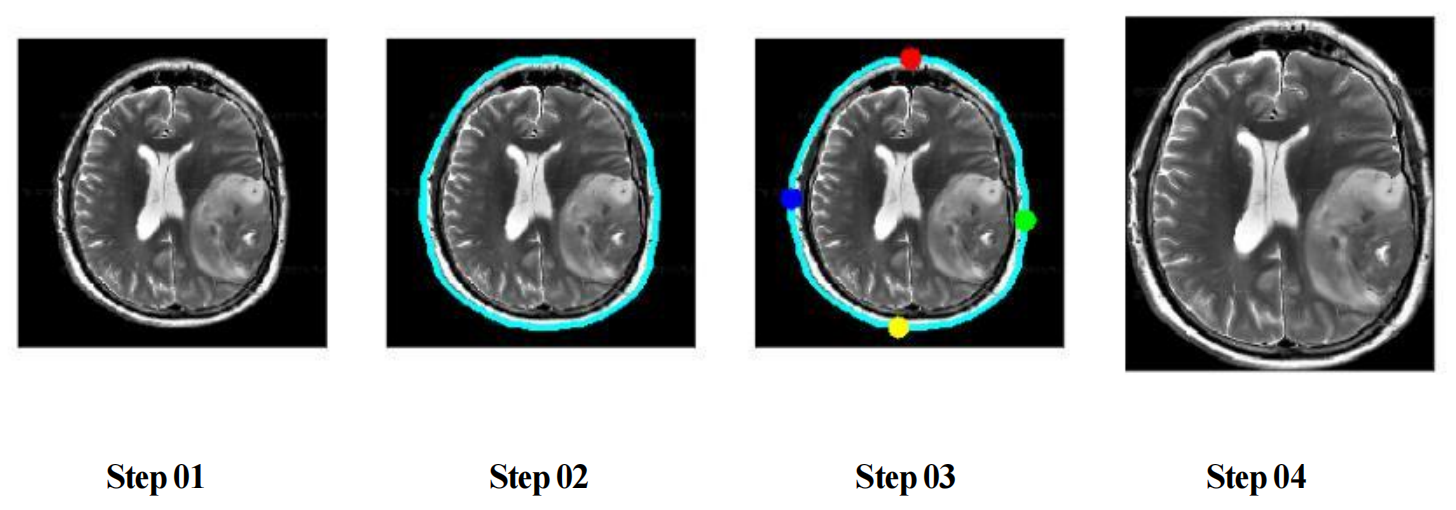
Additional preprocessing steps included:
- Conversion of grayscale MRI scans to three-channel RGB format
- Resizing all images to a uniform resolution of 224 × 224 pixels
- Pixel intensity normalization to stabilize training
Data augmentation
Given the limited size and imbalance of the dataset, data augmentation was applied exclusively to the training set to improve robustness and reduce overfitting. Augmentation operations included geometric transformations that preserve anatomical structure while increasing data diversity.
Applied augmentation techniques: rotation, horizontal and vertical flipping, scaling and minor translations. Figure 2 shows representative augmented examples from a single scan.
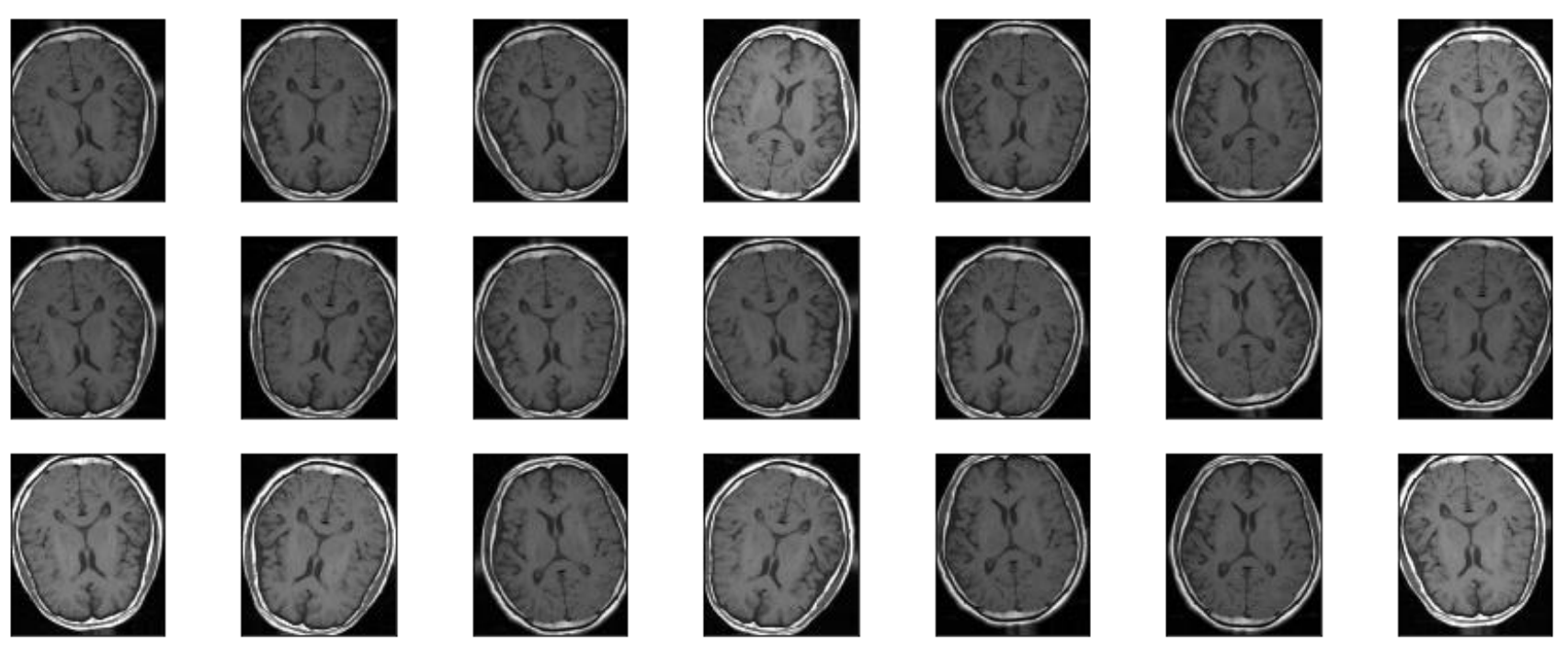
These transformations simulate real-world variability in MRI acquisition and enhance the model’s ability to generalize across unseen samples.
Methodology
Training pipeline
- Data: T1-weighted contrast-enhanced MRI; four classes (glioma, meningioma, pituitary tumor, no tumor); train/test split.
- Preprocessing: ROI cropping, grayscale→RGB, resize to 224×224, normalization; augmentation (rotation, flips, scaling) on training only.
- Models: Custom CNN trained from scratch vs. fine-tuned VGG-16, Xception, ResNet-50, Inception-V3.
- Training: Categorical cross-entropy loss; stochastic or adaptive optimizer; fixed epochs; validation monitored for overfitting.
- Evaluation: Same data splits and metrics across all models for fair comparison.
Model design
This work adopts a custom convolutional neural network (CNN) trained from scratch for multi-class brain tumor classification from MRI images. The architecture is designed to balance classification performance and computational efficiency, making it suitable for limited-data medical imaging scenarios (Figure 3).
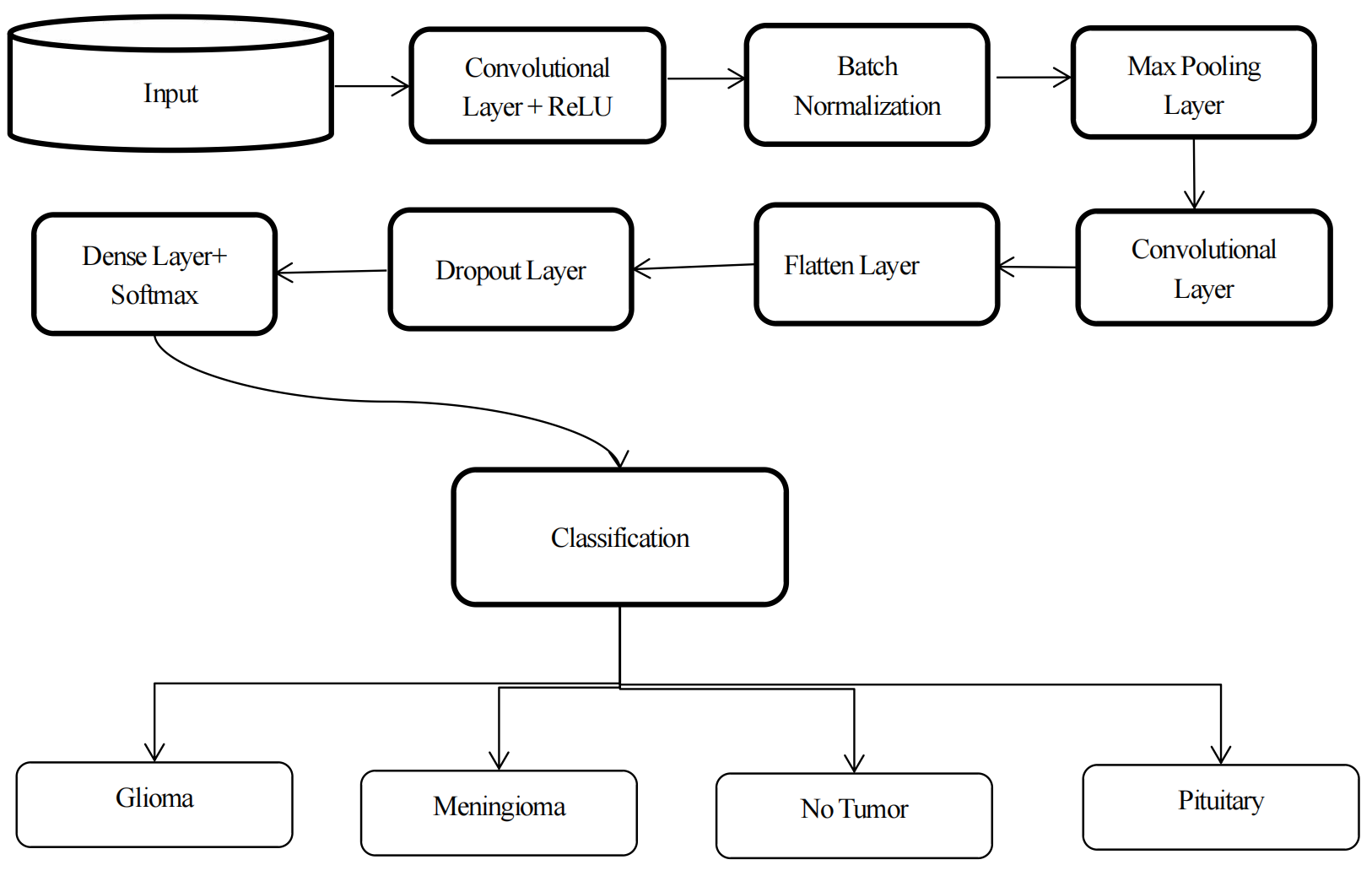
The network follows a sequential design with stacked convolutional blocks comprising convolution, ReLU activation, batch normalization, and max-pooling. Feature depth is progressively increased (64 → 512 filters) to capture hierarchical tumor representations, while batch normalization stabilizes training and pooling layers reduce spatial redundancy. The extracted features are flattened and passed through a dropout-regularized fully connected layer before softmax classification into four categories: glioma, meningioma, pituitary tumor, and no tumor.
This architecture intentionally avoids excessive depth and residual connections, prioritizing efficient feature learning over architectural complexity.
Training strategy
All models were trained using categorical cross-entropy loss for multi-class classification. Optimization strategies were selected based on model characteristics, with stochastic or adaptive optimizers employed to ensure stable convergence. Training was conducted for a fixed number of epochs, and validation performance was monitored to mitigate overfitting.
Baseline models and transfer learning setup
To contextualize the performance of the proposed CNN, comparisons were conducted against widely adopted transfer learning models:
- VGG-16
- Xception
- ResNet-50
- Inception-V3
These architectures were selected due to their proven effectiveness in image classification and frequent use in medical imaging research. For each baseline, the final classification layers were replaced to accommodate the four target classes, and fine-tuning was performed using the same preprocessed dataset. All models were trained under identical data splits and evaluation protocols to ensure fair comparison.
Model complexity comparison
A key objective of this study is to evaluate the trade-off between architectural complexity and classification performance. Table 2 summarizes the number of convolutional layers and trainable parameters for the proposed CNN and baseline models.
| Model | Convolutional layers | Parameters |
|---|---|---|
| Proposed CNN | 5 | 17,706,224 |
| VGG-16 | 13 | 14,815,044 |
| Xception | 71 | 21,262,892 |
| ResNet-50 | 48 | 49,681,540 |
| Inception-V3 | 48 | 22,007,588 |
Table 2. Model complexity: convolutional layers and trainable parameters.
Despite its relatively shallow depth, the proposed CNN achieves competitive performance while avoiding the substantial computational overhead associated with deeper transfer learning architectures. This supports the hypothesis that compact, task-specific CNNs can be effective alternatives to large pre-trained models in constrained medical imaging settings.
Results and evaluation
Training dynamics
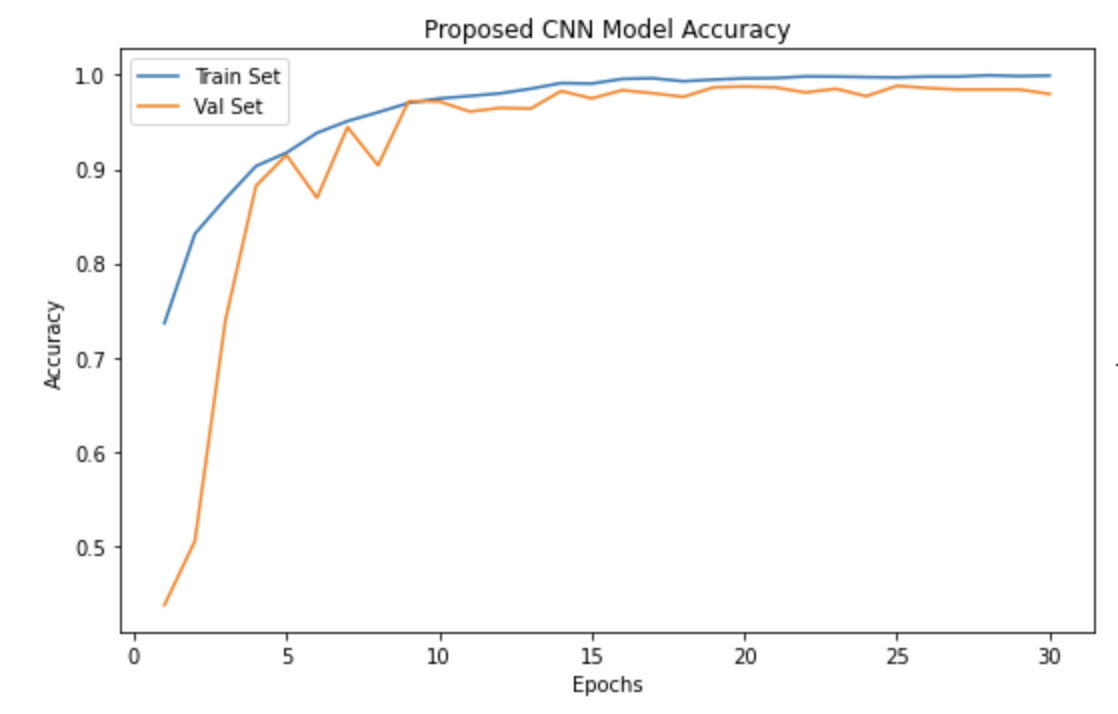
The proposed CNN demonstrates rapid convergence and stable optimization during training. As shown in Figure 4, training accuracy increases sharply within the first few epochs, while validation accuracy closely follows without significant divergence. This behavior indicates effective feature learning and controlled overfitting, despite the limited and imbalanced dataset.
The loss curves further confirm this trend: both training and validation loss decrease steadily and stabilize at low values, suggesting that the model generalizes well to unseen data. Minor fluctuations in validation performance are observed, which is expected in medical imaging tasks with small datasets.
In contrast, deeper transfer learning models such as ResNet-50 and Xception converge more slowly and exhibit larger gaps between training and validation curves (Figure 5), reflecting their higher capacity and increased susceptibility to overfitting under limited data conditions.
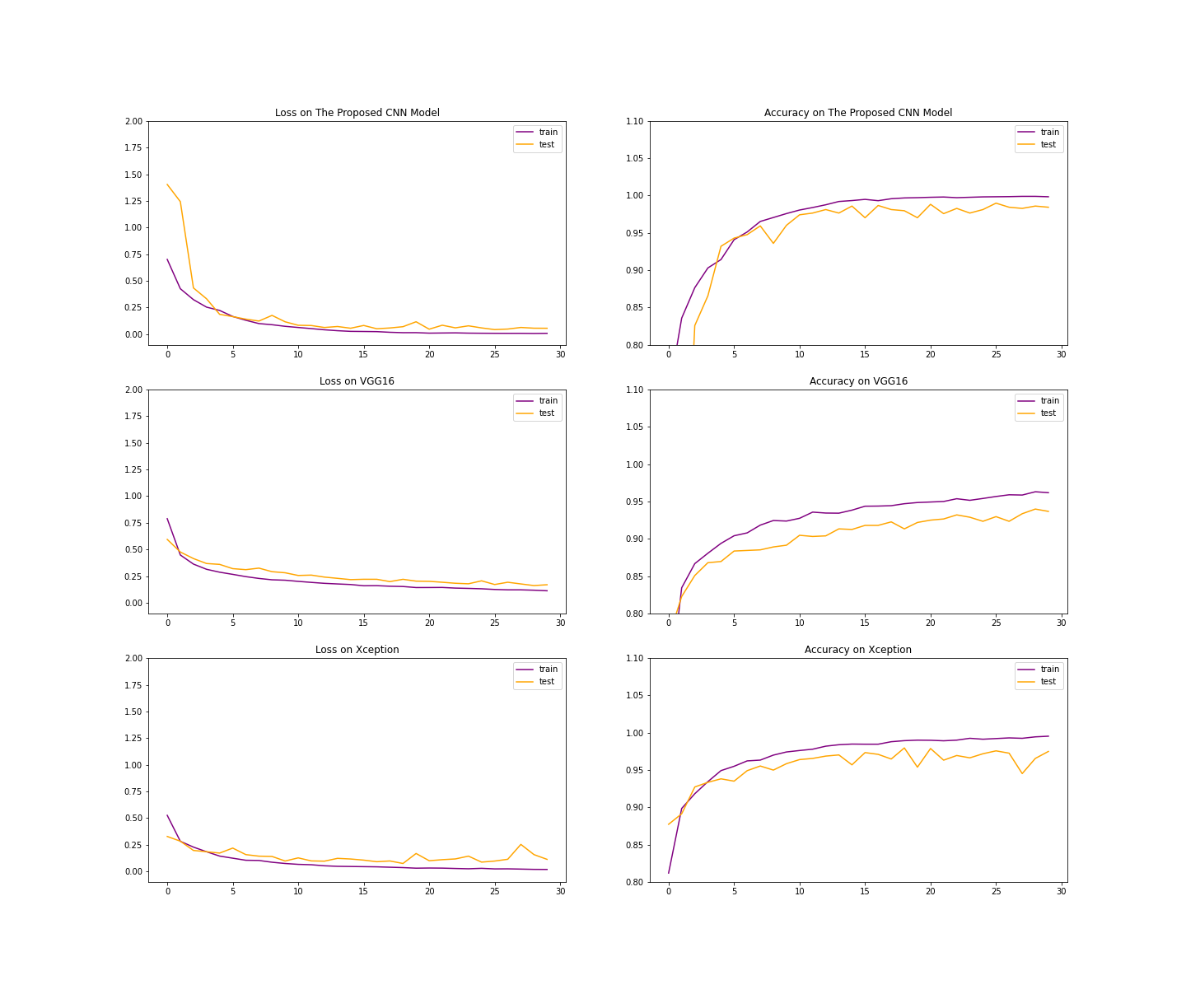
VGG-16 & Xception
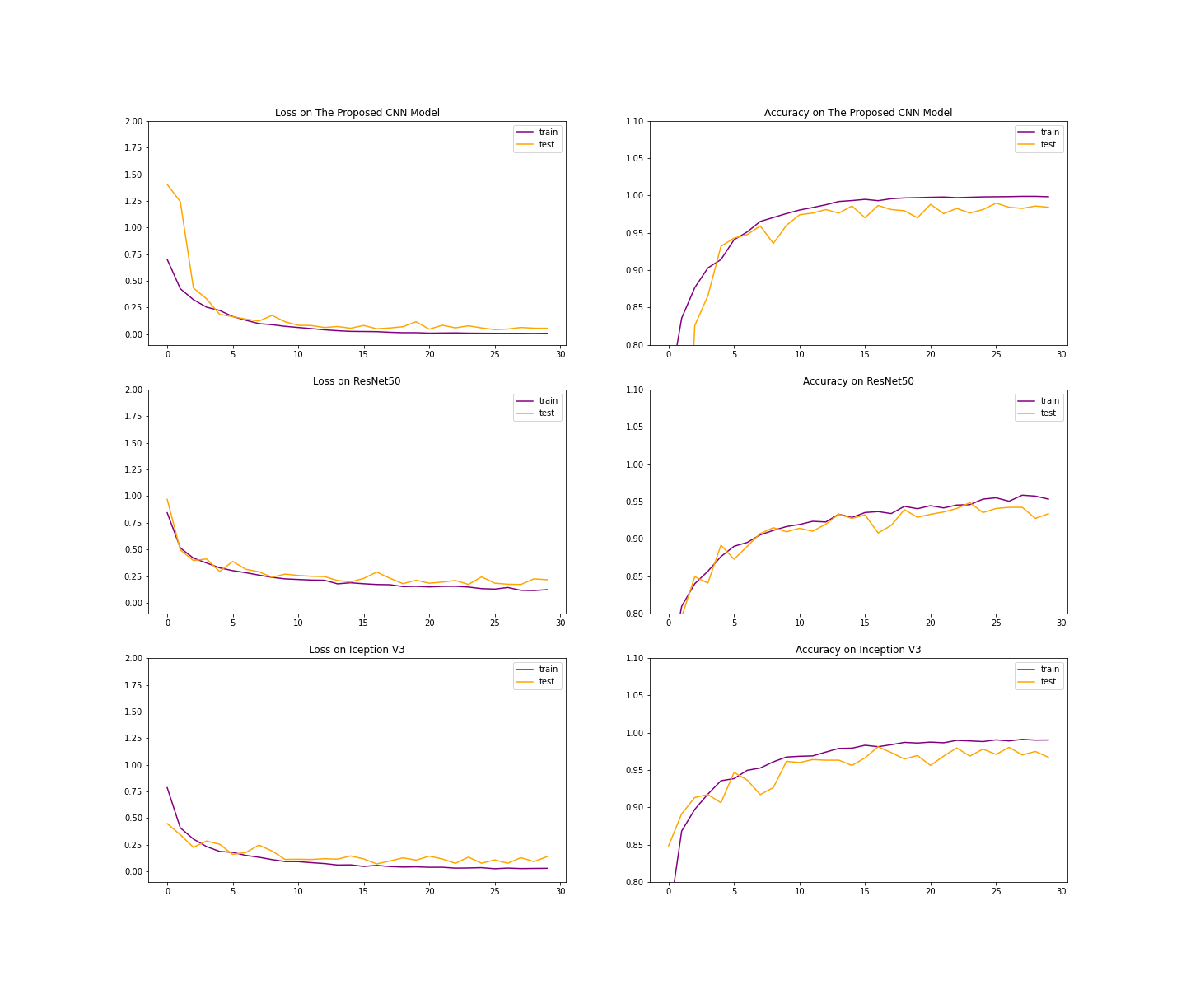
ResNet-50 & Inception-V3
Comparative performance analysis
To assess the effectiveness of the proposed CNN, its performance was compared against four widely used transfer learning architectures: VGG-16, Xception, ResNet-50, and Inception-V3. All models were trained and evaluated using the same dataset splits and preprocessing pipeline to ensure fairness.
Overall, the proposed CNN achieves the highest validation accuracy among all evaluated models while maintaining the lowest evaluation loss. Notably, it outperforms significantly deeper architectures such as ResNet-50 and Xception and remains competitive with Inception-V3, despite using substantially fewer convolutional layers.
These results support the hypothesis that compact, task-specific CNN architectures can outperform large pre-trained models when data availability and computational resources are constrained. Table 3 consolidates training and evaluation metrics across all models.
| Model | Training accuracy | Validation accuracy | Evaluation loss | Evaluation accuracy |
|---|---|---|---|---|
| Proposed CNN | 99.93% | 98% | 0.0542 | 99% |
| VGG-16 | 96% | 93% | 0.1765 | 93% |
| Xception | 99% | 95% | 0.2265 | 95% |
| ResNet-50 | 95% | 94% | 0.1539 | 94% |
| Inception-V3 | 99% | 97% | 0.0949 | 97% |
Table 3. Consolidated training and evaluation results across all models.
Key observations
- The proposed CNN achieves the best overall generalization performance, with the highest validation and evaluation accuracy.
- Transfer learning models show strong training accuracy but comparatively lower validation performance, indicating mild overfitting.
- Inception-V3 performs competitively but requires significantly greater architectural depth and computational complexity.
- The results highlight the effectiveness of training from scratch with careful architectural design for small-scale medical imaging tasks.
Limitations and future work
Limitations
- Limited dataset size and class imbalance: Small, publicly available MRI data with uneven class distribution; may limit robustness and increase sensitivity to bias.
- Single MRI modality: Only T1-weighted contrast-enhanced MRI; no T2 or FLAIR, so complementary tumor information is missing.
- No external clinical validation: Evaluated on a held-out split from the same source; not validated on independent, multi-institution datasets.
- Classification only: No tumor localization or segmentation, which are often needed for clinical decision support.
- Limited interpretability: No explainability techniques (e.g., Grad-CAM, saliency maps) to inspect model decisions.
Future work
- Multi-modal MRI: Integrate T1, T2, FLAIR (and other sequences) for more robust, clinically relevant diagnosis.
- External and cross-institutional validation: Test on independent datasets and different scanners/protocols to assess generalization.
- Segmentation and localization: Add spatial tumor information alongside classification.
- Interpretability and explainability: Use explainable AI (e.g., Grad-CAM) to highlight discriminative regions and support clinical trust.
- Deployment optimization: Further reduce model size and inference cost for edge or hospital workstations.
- Prospective clinical evaluation: Collaborate with clinicians to assess real-world utility and diagnostic impact.