Unsupervised Chest X-ray Clustering with Group Equivariant Convolutions

TL;DR
- We compare AlexNet with rotation augmentation vs P4M-equivariant CNN (no augmentation) for unsupervised chest X-ray clustering on NIH Chest X-ray.
- The equivariant model converges faster, shows more stable NMI, and clearer t-SNE cluster structure, with comparable accuracy (0.567 vs 0.564).
- Architectural equivariance is an effective alternative to data augmentation for robustness in deep clustering.
Abstract
Unsupervised clustering of chest X-ray images enables large-scale medical image analysis without reliance on manual annotations; however, conventional convolutional neural networks (CNNs) are limited in their ability to handle geometric transformations such as rotations and reflections, which commonly occur in radiographic data. In this work, we investigate unsupervised chest X-ray clustering using Group Equivariant Convolutional Networks within an iterative deep clustering framework. We compare two feature extraction strategies: an AlexNet-based model that relies on explicit rotation augmentation to improve robustness, and a P4M-equivariant convolutional network that encodes rotation and reflection equivariance directly into the architecture and operates without any data augmentation. Experiments on the NIH Chest X-ray dataset show that the equivariant model converges substantially faster and exhibits more stable clustering behavior, with Normalized Mutual Information (NMI) stabilizing early during training. Qualitative evaluation using t-SNE visualizations further reveals clearer cluster separation and more structured latent representations for the equivariant model. Both approaches achieve comparable downstream classification accuracy (0.564 for AlexNet and 0.567 for the P4M-equivariant CNN), while the equivariant model attains this performance without relying on data augmentation. These results demonstrate that architectural equivariance provides an effective alternative to augmentation-based robustness in unsupervised chest X-ray clustering.
Key contributions
- Systematically study geometric equivariance in unsupervised chest X-ray clustering.
- Integrate group-equivariant CNNs into a deep clustering framework.
- Demonstrate that architectural equivariance improves feature consistency with reduced reliance on augmentation.
Training pipeline
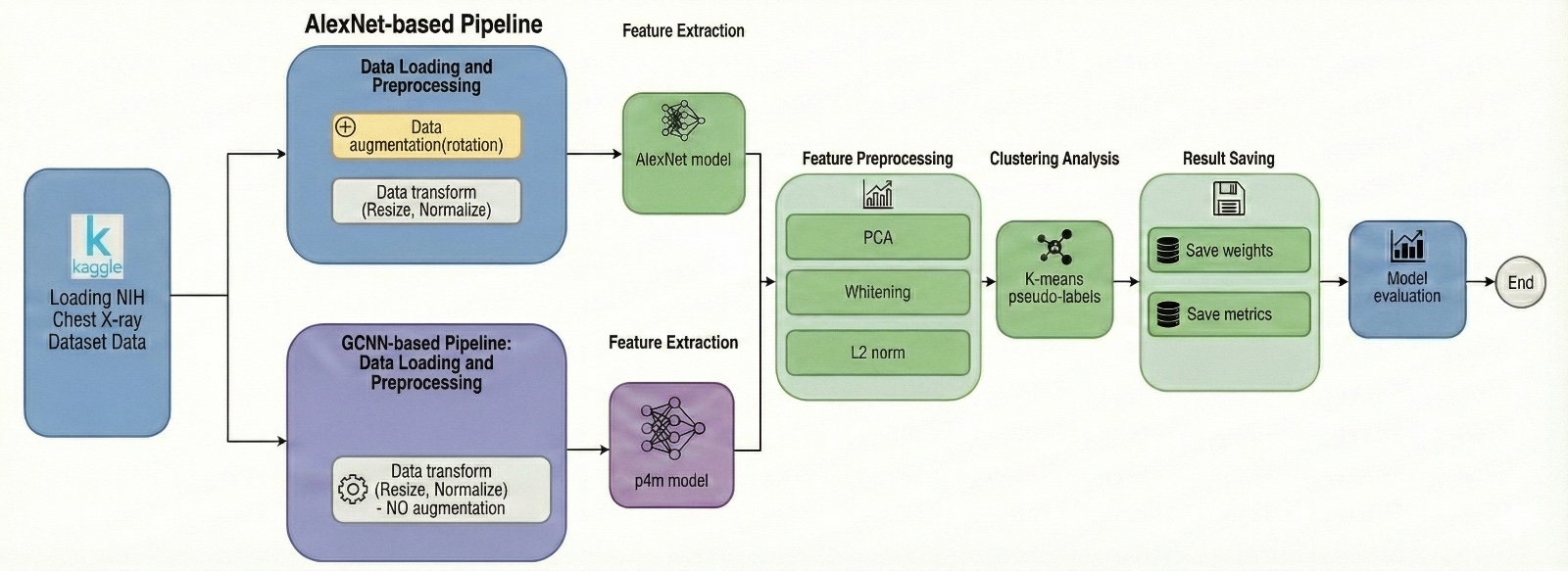
Objective
The objective of this work is to evaluate whether group-equivariant convolutional networks can replace data augmentation–based robustness in unsupervised medical image clustering. To this end, we compare a standard convolutional neural network (AlexNet) with a P4M group-equivariant CNN under an otherwise identical DeepCluster-style unsupervised clustering framework.
This project builds upon the DeepCluster framework introduced in Deep Clustering for Unsupervised Learning of Visual Features (Caron et al.), extending it with group-equivariant convolutional architectures for medical image clustering.
Data preparation
Experiments are conducted on the NIH Chest X-ray dataset. Chest X-rays are among the most frequent and cost-effective medical imaging exams, but large publicly available labeled datasets have been scarce, limiting progress in computer-aided detection. The NIH dataset comprises 112,120 frontal X-ray images from 30,805 unique patients.
For unsupervised clustering, we remove the disease labels and use only the images. All images are resized to 64 × 64 pixels and normalized to the range [−1, 1] to ensure consistent input across models.
Feature extraction backbones
Two parallel feature-extraction pipelines are evaluated:
-
AlexNet (standard CNN): Serves as a conventional baseline and relies on explicit rotation-based data augmentation to improve robustness to geometric variations.
-
P4M group-equivariant CNN: Employs group convolutions and group pooling to encode rotation and reflection equivariance directly into the network architecture. No geometric data augmentation is applied, allowing a direct assessment of architectural equivariance.
Both networks produce high-dimensional feature embeddings for each input image.
Feature preprocessing
To obtain compact and clustering-friendly representations, extracted features undergo a standard preprocessing pipeline:
- Principal Component Analysis (PCA) for dimensionality reduction
- Whitening to decorrelate features and equalize variance
- L2 normalization to stabilize distance-based clustering
Unsupervised clustering
The processed embeddings are clustered using K-means, yielding cluster assignments that serve as pseudo-labels. These labels represent the model’s current estimate of semantic grouping in the absence of ground-truth annotations.
Iterative training loop
Training follows an iterative deep clustering procedure. At each iteration, the network is trained using cross-entropy loss on the pseudo-labels; features are then re-extracted, re-clustered, and used to update the model. This loop progressively refines both the learned representations and the cluster structure.
Evaluation
Model checkpoints and clustering metrics are recorded throughout training. Performance is assessed through clustering stability metrics and qualitative visualization of the learned embedding space, enabling a direct comparison between augmentation-based and equivariance-based approaches.
Results
1. Clustering convergence and stability
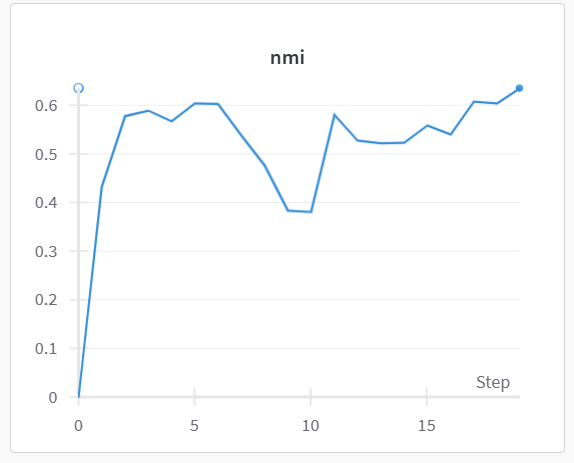
AlexNet
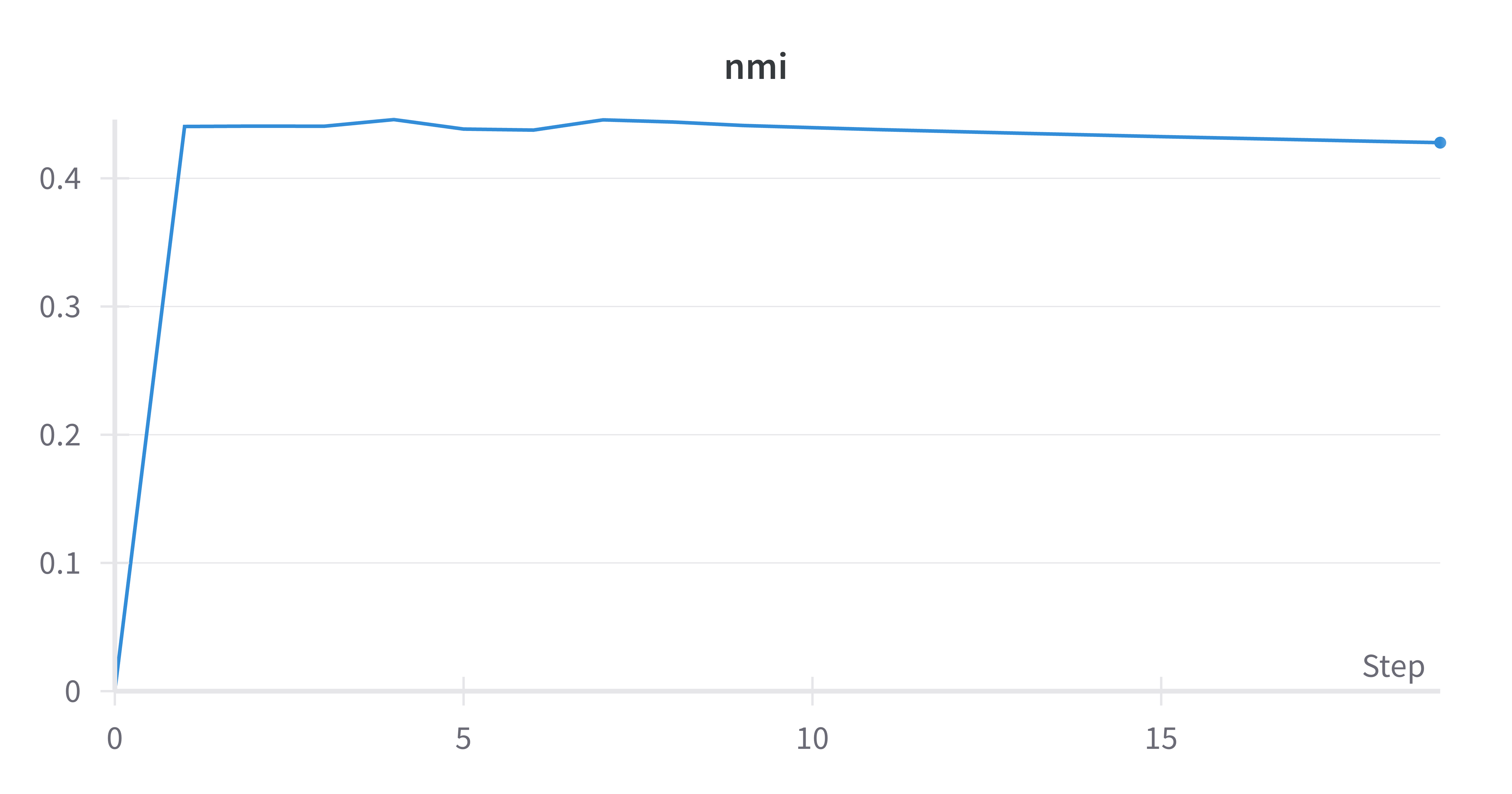
P4M-equivariant CNN
Interpretation. The AlexNet-based pipeline shows a gradual increase in NMI with noticeable fluctuations across iterations, indicating sensitivity to pseudo-label updates and reliance on data augmentation for stability. In contrast, the P4M-equivariant CNN reaches a stable NMI value within the first few iterations and maintains it throughout training. This early stabilization suggests that encoding rotation and reflection equivariance directly into the architecture leads to more consistent cluster assignments without requiring geometric augmentation.
2. Optimization behavior
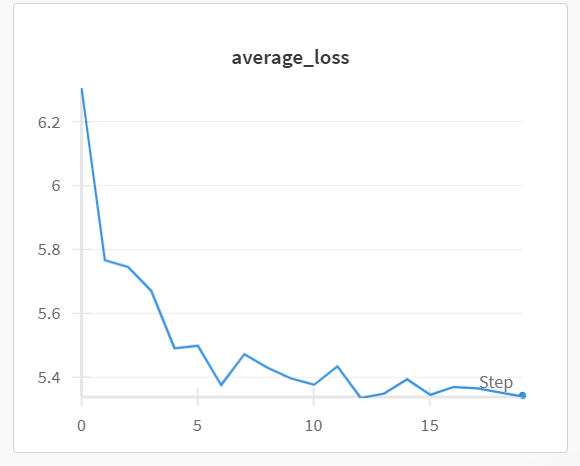
AlexNet
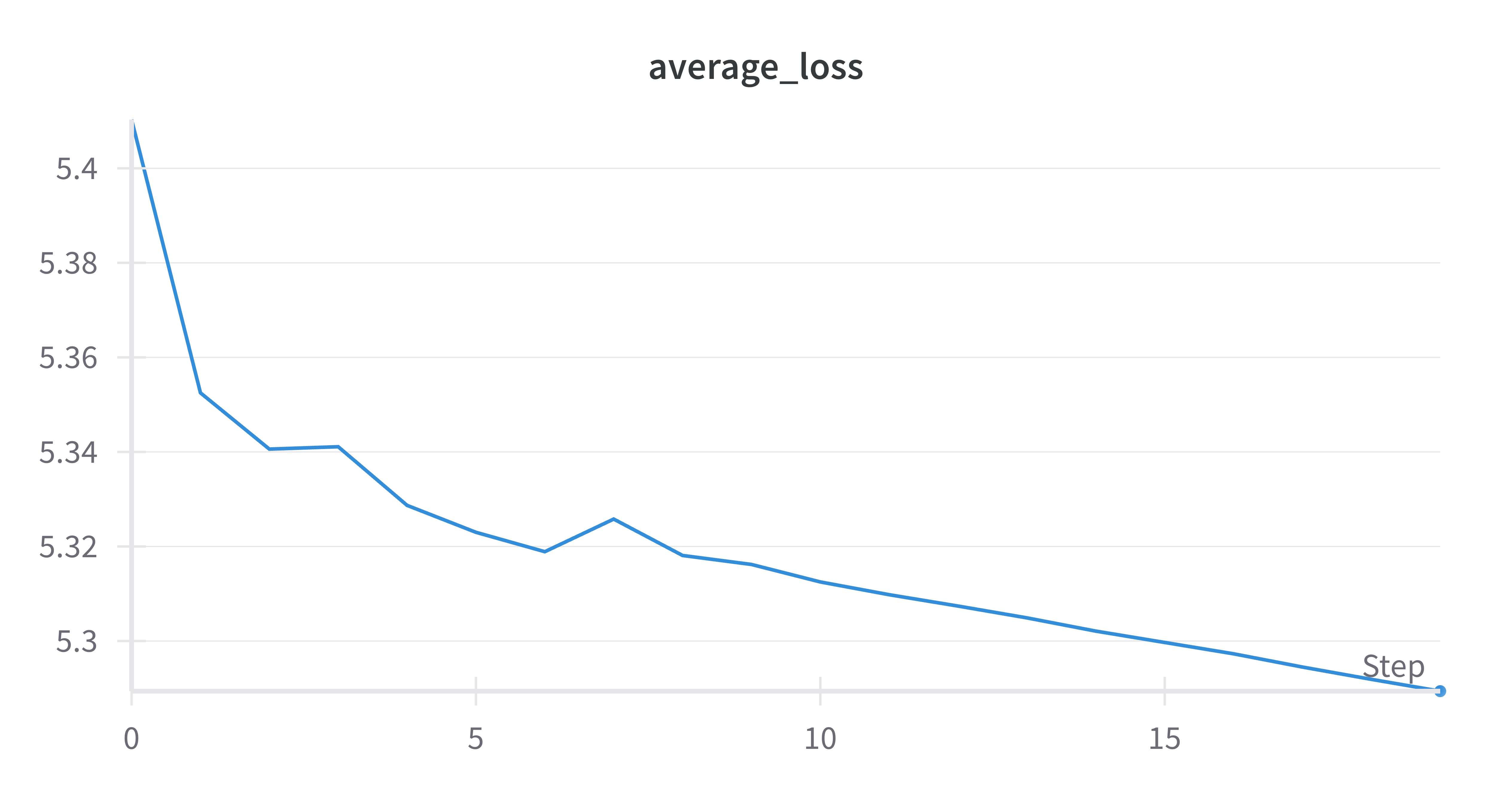
P4M-equivariant CNN
Interpretation. Both models exhibit a decreasing loss trend, indicating effective optimization under the iterative clustering framework. However, the P4M model shows a smoother and more monotonic loss trajectory, while the AlexNet model displays small oscillations. This further supports the observation that architectural equivariance contributes to more stable training dynamics.
3. Embedding space structure

AlexNet

P4M-equivariant CNN
Interpretation. The AlexNet embeddings form overlapping and loosely organized clusters, suggesting limited separation in the latent space. In contrast, the P4M-equivariant CNN produces more compact and clearly separated clusters. This qualitative difference indicates that group-equivariant convolutions learn a more structured representation space, even in the absence of geometric data augmentation.
4. Linear probing
We evaluate linear probing by training a logistic-regression classifier on the frozen features to predict cluster assignments. G-CNN features achieve higher logistic-regression accuracy than the CNN baseline (0.567 vs. 0.564), indicating more transferable representations despite the P4M model being trained without geometric data augmentation.
5. Summary of key findings
- Faster convergence: The P4M-equivariant CNN stabilizes clustering performance early in training.
- Improved stability: Reduced fluctuations in both NMI and loss compared to AlexNet.
- More structured representations: Clearer cluster separation in t-SNE visualizations.
- Better transferability: Higher linear-probing accuracy (0.567 vs. 0.564) for G-CNN features.
- No augmentation required: Comparable representation quality is achieved without rotation-based data augmentation.
Limitations and Future work
Limitations
- K-means scalability: K-means becomes a bottleneck on large, complex datasets.
- Pseudo-label dependency: Training stability strongly depends on pseudo-label quality; noisy labels can propagate across iterations.
- Medical data ambiguity: Chest X-ray data is high-variance and often multi-label, making cluster–label alignment harder.
Future work
- Scalable clustering: Explore hierarchical or graph-based clustering alternatives.
- Better pseudo-labeling: Integrate more robust label generation (e.g., self-supervised learning).
- Richer settings: Extend to multi-view / multi-label (and potentially multi-modal) learning.